Kafka consumer flow-trigger
9 minute read
Overview
This is a flow-trigger that enables triggering a flow that consumes messages from Apache Kafka. Using Apache Kafka is useful when implementing an event-driven microservice architecture.
It is part of the Kafka plugin, @axway/api-builder-plugin-ft-kafka. The plugin also contains a Kafka Producer flow-node. They can be used independently in that your application may only just consume messages from Kafka, it does not necessarily have to produce them.
You can install the Kafka plugin from the Plugins page, or execute the following command:
npm install @axway/api-builder-plugin-ft-kafka
For additional getting started information, refer to the Getting Started With API Builder.
Flow-trigger details
The following sections provide details of the available Kafka Consumer parameters.
Connection parameters
| Parameter | Type | Description | Configuration selection | Required |
|---|---|---|---|---|
| Client ID | String | Identifies this application as a specific member of the consumer group (for example, “client-1”). | Selector, String | Yes |
| Brokers | String | A comma separated list of host:port (for example, “localhost:9092”). | Selector, String | Yes |
| Reject unauthorized SSL | String | Rejects unauthorized SSL certificates. | Selector, String | No |
| CA certificate | String | The path to a CA certificate file to trust (PEM format). This is relative to your API Builder project directory. | Selector, String | No |
| Client key | String | The path to a client key file (PEM format). This is relative to your API Builder project directory. | Selector, String | No |
| Client certificate | String | The path to a client certificate file (PEM format). This is relative to your API Builder project directory. | Selector, String | No |
| Retries | String | The maximum number of retries per call. | Selector, String | No |
Note
There is only one Kafka Connection configuration managed by the UI. All Kafka flow-triggers share the same Connection configuration and have the Connection ID “kafka”.Trigger parameters
| Parameter | Type | Description | Configuration selection | Required |
|---|---|---|---|---|
| Consumer group ID | String | Identifies this application as a member of a collective group of consumer instances, identified by a `groupId`. In a horizontally scaled application, each instance would be a consumer and together they act as a consumer group. | Selector, String | Yes |
| Topic | String | The topic to listen for events when data is written to this particular topic. | Selector, String | Yes |
| From beginning | String | The consumer group will use the latest committed offset when starting to fetch messages. If the offset is invalid or not defined, this option defines the behavior of the consumer group. If “true”, it will start reading from the earliest offset. If “false”, it will use the latest. | Selector, String | No |
| Session timeout (msec) | String | Timeout in milliseconds used to detect failures. The consumer sends periodic heartbeats to indicate its liveness to the broker. If no heartbeats are received by the broker before the expiration of this session timeout, then the broker will remove this consumer from the group and initiate a rebalance. | Selector, String | No |
| Rebalance timeout (msec) | String | The maximum time that the coordinator will wait for each member to rejoin when rebalancing the group. | Selector, String | No |
| Heartbeat interval (msec) | String | The expected time in milliseconds between heartbeats to the consumer coordinator. Heartbeats are used to ensure that the consumer’s session stays active. The value must be set lower than session timeout. | Selector, String | No |
| Allow auto-topic creation | String | Allows topic creation when querying metadata for non-existent topics. | Selector, String | No |
| Meta-data maximum age (msec) | String | The period of time in milliseconds after which we force a refresh of metadata even if we have not seen any partition leadership changes to proactively discover any new brokers or partitions. | Selector, String | No |
| Max bytes per partition | String | The maximum amount of data per-partition the server will return. This size must be at least as large as the maximum message size the server allows or else it is possible for the producer to send messages larger than the consumer can fetch. If that happens, the consumer can get stuck trying to fetch a large message on a certain partition. | Selector, String | No |
| Min bytes | String | Minimum amount of data the server should return for a fetch request, otherwise wait up to maxWaitTimeInMs for more data to accumulate. | Selector, String | No |
| Max bytes | String | Maximum amount of bytes to accumulate in the response. Supported by Kafka >= 0.10.1.0. | Selector, String | No |
| Maximum wait time (msec) | String | The maximum amount of time in milliseconds the server will block before answering the fetch request if there is not sufficient data to immediately satisfy the requirement given by minBytes. | Selector, String | No |
| Partitions consumed concurrently | String | The number of partitions to consume concurrently. | Selector, String | No |
| Read uncommitted messages | String | Configures the consumer isolation level. If false (default), the consumer will not return any transactional messages which were not committed (default false). | Selector, String | No |
| Message format | String | The message format for messages on `topic` which will be used when decoding messages. If you do not know the message format, then use `binary`. One of: JSON | string | binary |
Quick start
We recommend that you first get familiar with Kafka Key Concepts.
To get started using the Kafka flow-trigger, you need to have access to a Kafka server. You can follow this guide, Running Kafka in Development for steps to run Kafka and Zookeeper in a Docker container.
Alternatively, if you do not wish to use Docker, you can download Kafka directly and extract into a directory. You must start zookeeper first:
// Start zookeeper
./bin/zookeeper-server-start.sh config/zookeeper.properties
After zookeeper starts, you can start Kafka:
// Start kafka
./bin/kafka-server-start.sh config/server.properties
When shutting down, shutdown Kafka first, and then zookeeper.
How to use the Kafka Consumer flow-trigger
Example - Consume JSON messages
For this example, we will create a “Consumer flow” and configure it to consume JSON messages from a Kafka topic, “messages”. Generally speaking, your application would be unlikely to read and write to the same topic. However, to demonstrate this example, we will also create a “Producer flow” to write JSON to the Kafka topic, “messages”.
Create a consumer flow
Follow the instructions on Create a new flow to create a “Consumer flow”. In this flow, you will want to drag the Kafka Consumer from the Flow-Nodes > Flow-Triggers panel on the left, into the flow graph on the right. Configure the Kafka Consumer flow-trigger as shown below. The Consumer group ID is integral to the scalability of Kafka. For example, you can configure multiple instances of API Builder with the same Consumer group ID to achieve scalability.
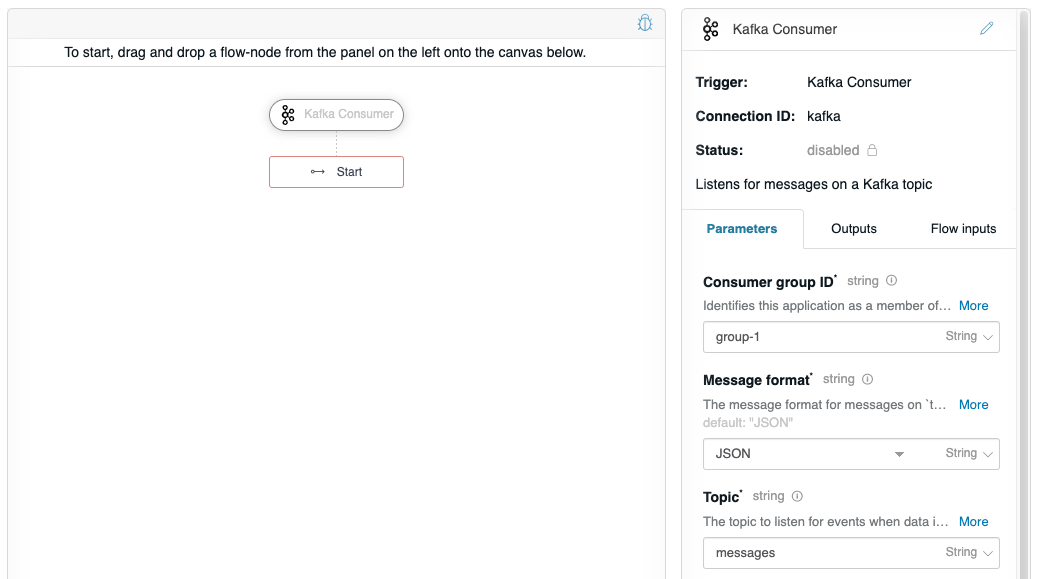
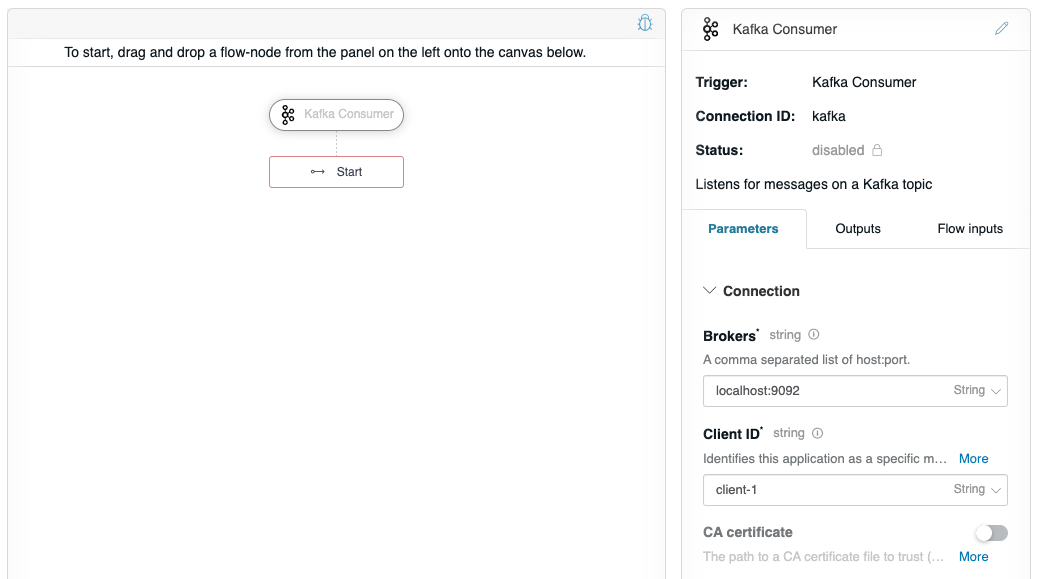
This configures the Kafka Consumer to receive JSON messages from the “messages” topic. However, we also need to configure the Connection details. Scroll the Kafka Consumer property panel to the bottom, and enter your Kafka server’s details. This example is using “localhost:9092” and is uniquely identifying this service as a unique “client-1” for Client ID.
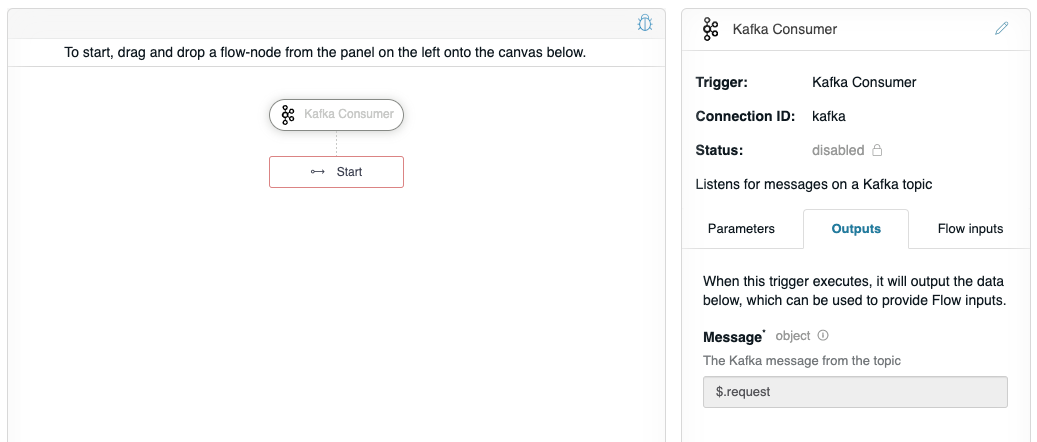
We will also want to do something with the Kafka message in the flow, but first we need to understand what a Kafka Message actually is so that we can work with it. The Kafka Consumer outputs a Message value called $.request, which can be seen on the Outputs tab.
If you click the info icon  , it will display the JSON schema for a Message. In this example, we are only interested in the
, it will display the JSON schema for a Message. In this example, we are only interested in the value.
// JSON schema for Message
{
"properties": {
"value": {
"description": "The message payload. The type of data depends on the configured \"Message format\"."
},
"key": {
"description": "The message key encoded as a buffer.",
"oneOf": [
{
"type": "object"
},
{
"type": "null"
}
]
},
"headers": {
"type": "object",
"description": "Key-value pairs of message headers.",
"additionalProperties": {
"type": "object",
"description": "The header value encoded as a buffer."
}
},
"offset": {
"type": "string",
"description": "The current consumer position."
},
"timestamp": {
"type": "string",
"description": "The number of milliseconds since the Unix epoch."
}
}
}
So to configure this flow to use the Message value, click on the Flow inputs tab, and edit the request input as shown below.
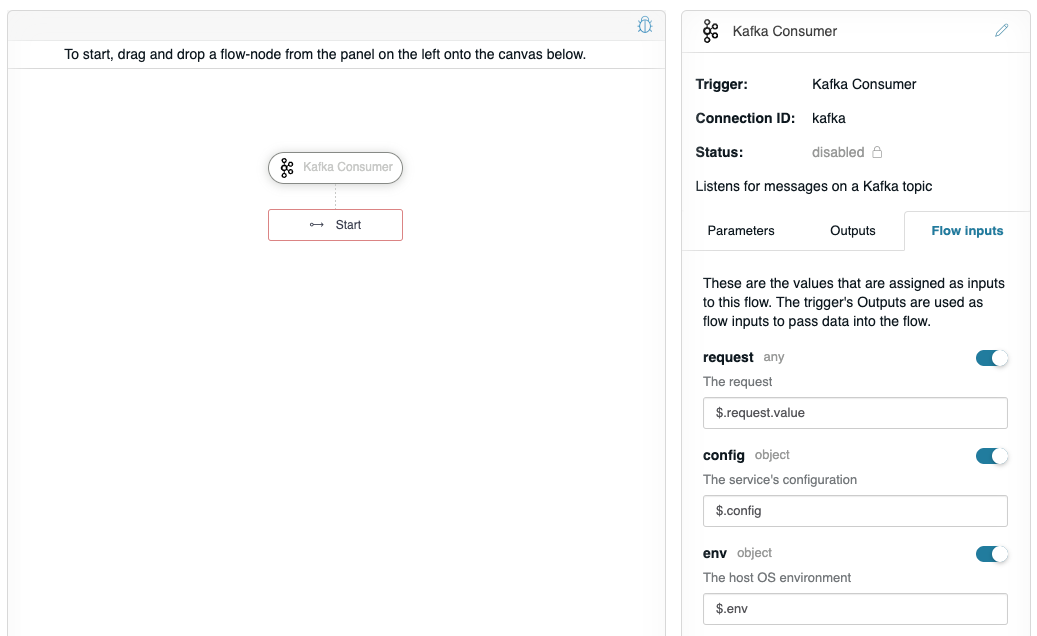
This configures the Kafka Consumer to provide the output Message value as input into the flow.
On the Flow inputs tab, it lists the optional named inputs that can be provided to the flow: request, config, and env. These keys are hard-coded into the flow and their JSONPath selectors are provided automatically. The request maps the output of the Kafka Consumer as input into the flow, so we want change the value to use $.request.value as the value of request (this selects the value property from the Message object). From within the flow, the respective input values can be accessed as $.request, $.config, and $.env.
Now, let’s do something with $.request by adding the Mustache flow-node to the graph, and configuring Data to be $.request, and the Template to be “{{data.message}}” (without quotes).
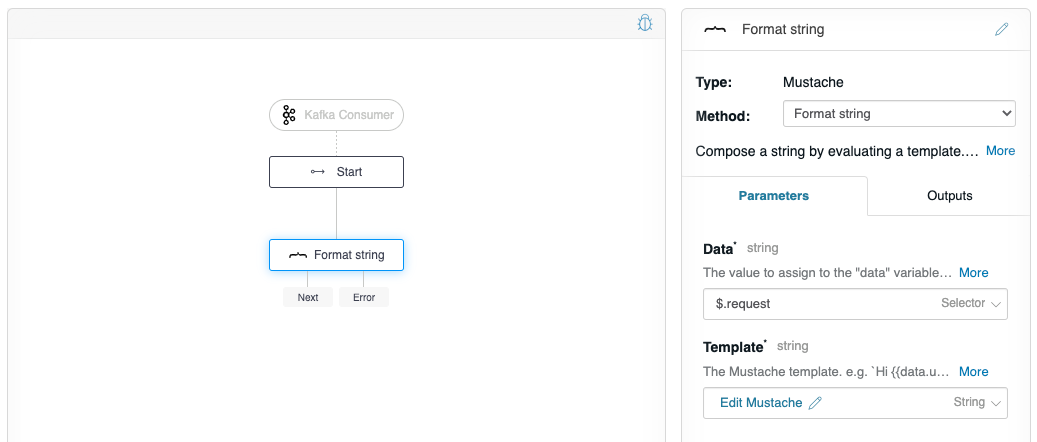
Now the flow is ready to be triggered by a Kafka Producer. However, let’s verify that the flow works as expected. Click on the debugger icon in the upper-right of the graph to reveal the debug panel. Change the “request” to have a JSON message with the value “banana” as we plan on this flow receiving a JSON input from the “Producer flow”.
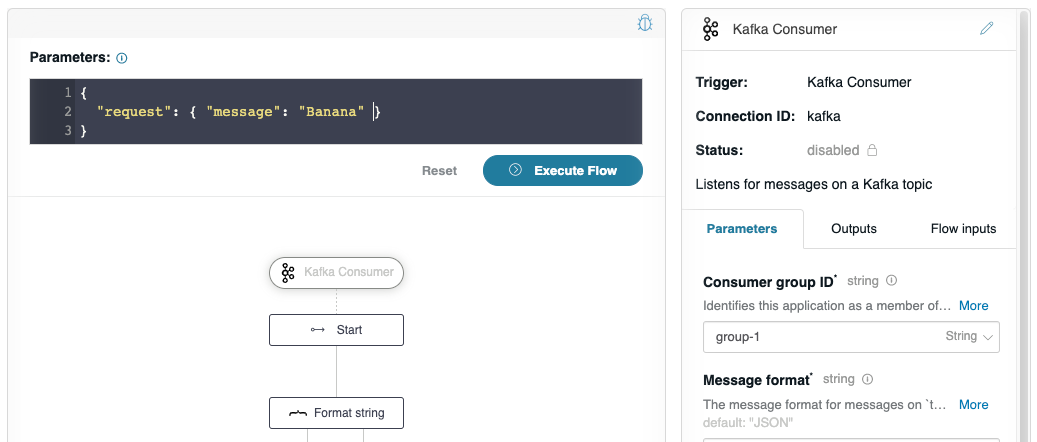
Click Execute Flow. The flow editor will not show much, just a message, “Flow successfully executed with no response”. However, if you check the console window where you launched your API Builder project, you see a detailed debug log showing the execution, and that it handled the “banana” message as expected:
// Flow output
1618583651686 DEBUG [request-id: 38b6f1ca-5fac-4b88-aefe-4f428f2b1e17] Flow invoked by debugger: Consumer
1618583651687 DEBUG [request-id: 38b6f1ca-5fac-4b88-aefe-4f428f2b1e17] Waiting: Format string (mustache.1)
1618583651687 DEBUG [request-id: 38b6f1ca-5fac-4b88-aefe-4f428f2b1e17] Invoking: Format string (mustache.1)
1618583651688 DEBUG [request-id: 38b6f1ca-5fac-4b88-aefe-4f428f2b1e17] finished flow-node Format string (mustache.1) route: []
1618583651688 DEBUG [request-id: 38b6f1ca-5fac-4b88-aefe-4f428f2b1e17] Format string (mustache.1) writing "Banana" to ctx as: $.value
1618583651689 DEBUG [request-id: 38b6f1ca-5fac-4b88-aefe-4f428f2b1e17] Flow debugging completed: Consumer
After, you can click Apply to save the flow. If all goes well, the Status of the Kafka Consumer flow-trigger will change to enabled. If there are any errors, you may need to check connectivity.
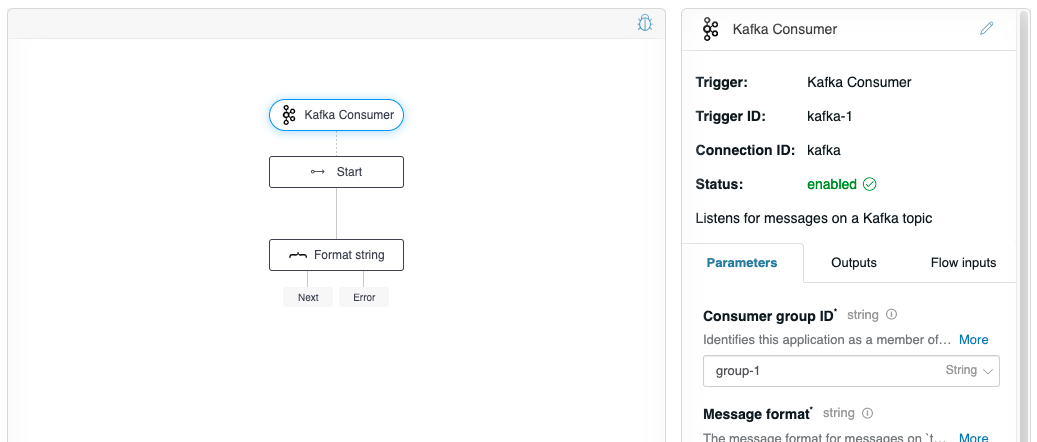
Create a producer flow
Follow the instructions on Create a new flow to create a “Producer flow”. In this flow, you will want to drag the Kafka Producer from the Flow-Nodes > Flow-Triggers panel on the left, into the flow graph on the right. Configure the flow-node to have the properties as shown below.
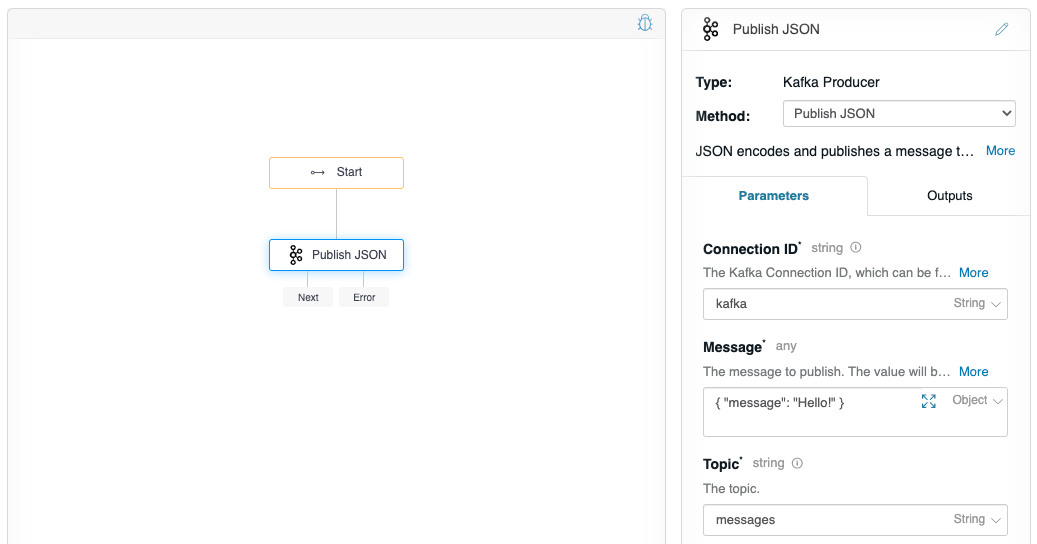
Click on the debugger icon in the upper-right of the graph, do not change any values, and click Execute Flow, and check your console debug log, you should see:
Format string (mustache.1) writing “Hello!” to ctx as: $.value